
Research
My research spans reinforcement learning — especially multi-task RL — and large language models. Within RL, I am most interested in why naïve multi-task PPO collapses on tail tasks — how value normalization, critic conditioning, and inter-task gradient interactions combine to stall hard tasks — and in designing principled, lightweight remedies that recover tail-task performance without enlarging the model.
More recently, since May 2026, I have started an early-stage second direction on multi-objective reinforcement learning for LLM post-training (Probe-FairGRPO). It studies multi-reward GRPO through a multi-task RL lens, using probe-based gradient Gram matrices and fair-gradient weighting to diagnose and balance competing reward objectives during post-training.
I work with my advisors Prof. Annie Qu and Prof. Rui Miao at UC Irvine.
A list of my articles is also available on my Google Scholar profile.
Manuscripts under review
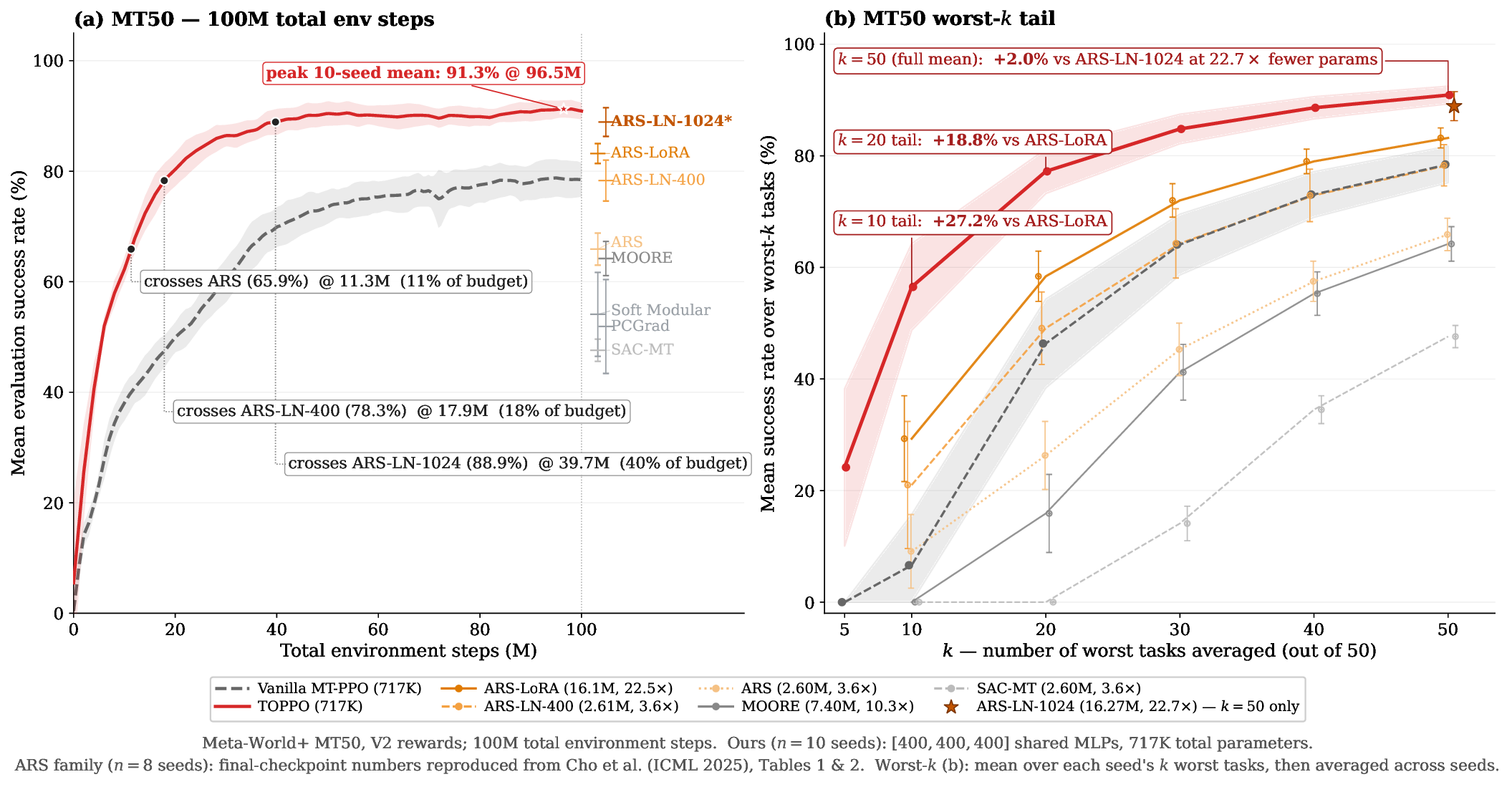
TOPPO: Rethinking PPO for Multi-Task Reinforcement Learning with Critic Balancing
Multi-task PPO suffers from critic-side gradient ill-conditioning where tail tasks stall while easy tasks dominate value-function updates. We introduce Critic Balancing — per-task PopArt value normalization, pre-activation LayerNorm in the critic body, and per-side gradient combiners (PCGrad / CAGrad / FairGrad chosen independently for actor...